Abstract
No matter for what kind of many screenplays, the most common topics among those watcher or fans are probably:
- Which xxx is the best?
- Which xxx do you recommend?
- Do you think what’s the best xxx of 2021?
xxx here can be substituted by any type of screenplays, i.e. movies, TV series, TV show and etc. This rule applies to one type of screenplays as well - TV anime.
In this post, I would present my analysis on what’s most welcomed TV animes in different period of time and what are the potential features make them become popular among viewers, with the help the data from anime community in Reddit and anime record data.
Background
TV series in US usually have 23-24 episode as a “full season” and many of them run across the fall and winter, in between late September to May of the next year. However, unlike the conventions in North America, anime producers in Japan had very different traditions. The TV animes in Japan are usually played by seasons and last for three months, containing 12-13 episodes:
- Winter: January - March
- Spring: April - June
- Summer: July - September
- Fall: October - December
Therefore, in the project I would divide the animes in each year into four groups by natural seasons as the release time for the most episodes of an anime would fall into one of the four season, meaning if two animes belong to the same season, their release time of each episode would be very close
Besides, the genres of the animes could very rich, covering a lot of topics and multiple themes, so we would be able to analyze if there is any potential connections between genres and the popularity.

Finding the Hotest Anime in Different Period
How to Extract the Data We Want?
First of all, we need to determine what submissions are we actually want. Unlike IMDB or Rotten Tomatoes, there is no individual page in reddit for each anime so that people would only discuss or review that specific work under such page. The topics could be relatively spare and board. This can be also proved by a word cloud.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(width = 1000, height = 600, background_color="white",
min_font_size = 16, font_step=2)
wordcloud.generate(sub_titles['text'].str.cat(sep=' '))
plt.figure(figsize=(20, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Word cloud of title data among all submission in anime subreddit from
text_submissionsdataset
From the word cloud we can see that, people discussed a lot topics in this subreddit, including but not limited to plots, characters they like, anime recommendations. It would be difficult for us to determine if they are talking about a specific anime and if they are talking about the animes currently on air or not by simply applying LatentDirichletAllocation from scikit-learn. As it’s very likely that the model will fail to extract the name of the anime properly.
Fortunately, The moderators of the anime subreddit and other contributors wrote a post bot4 which monitors the latest streaming info and will create a post automatically for each episode of anime after it’s released. And this is bot is currently operates under the account AutoLovepon.
A typical discussion submission created by this bot
Then we can simple go through the full data set we have, select the posts created by AutoLovepon, and use regex to extract anime title and episode number. Besides, since the full data set only contains meta data, I also used the praw library to help obtain the title name from reddit. As a result, we can acquire the data like below:
anime: title of animecreated_utc: date this submission created, which can be used to identify which season this anime belongs tocom_mean,com_median,com_count: The mean, median of the scores of the comments under this submission and count the total commentsscore: The score of this submission
sta_19[sta_19['anime'] == "One Punch Man Season 2"].head()
| id | created_utc | anime | season | ep | com_mean | com_median | com_count | score | |
|---|---|---|---|---|---|---|---|---|---|
| 749 | t3_bbatev | 2019-04-09 17:34:10 | One Punch Man Season 2 | 2 | 1.0 | 26.809337 | 2.0 | 2035.0 | 7756 |
| 784 | t3_bdwte2 | 2019-04-16 17:40:48 | One Punch Man Season 2 | 2 | 2.0 | 24.634706 | 2.0 | 1919.0 | 3743 |
| 830 | t3_bgja8c | 2019-04-23 17:39:02 | One Punch Man Season 2 | 2 | 3.0 | 42.697674 | 3.0 | 1290.0 | 5468 |
| 881 | t3_bj65ne | 2019-04-30 17:37:40 | One Punch Man Season 2 | 2 | 4.0 | 28.279570 | 3.0 | 930.0 | 3887 |
| 927 | t3_bltood | 2019-05-07 17:42:06 | One Punch Man Season 2 | 2 | 5.0 | 22.986000 | 3.0 | 1000.0 | 2530 |
Rank Top 5 Animes of each season
The score of each discussion submission the most obvious data we can use to compare. Thus, we can calculate the mean of each anime’s discussion submission’s mean and rank them.
import plotly.express as px
top5_by_score = mean_scores.groupby('season').apply(lambda x: x.sort_values(by='score', ascending=False, na_position='first').head(5).reset_index()).droplevel(0)
fig = px.line(
top5_by_score,
x=top5_by_score.index,
y='score',
color='season',
symbol='season',
hover_data=['anime'],
labels={
"index": "Rank",
"score": "Mean of Submission Score",
"season": "Season"
},
)
fig.show()
rank_2019 = rank_seasons(2019)
rank_2019
| anime | score | season | |
|---|---|---|---|
| 0 | Kaguya-sama wa Kokurasetai: Tensai-tachi no Re... | 7204.916667 | 1 |
| 1 | Mob Psycho 100 Season 2 | 6884.000000 | 1 |
| 2 | Yakusoku no Neverland | 4324.083333 | 1 |
| 3 | Tate no Yuusha no Nariagari | 3800.400000 | 1 |
| 4 | Tensei shitara Slime Datta Ken | 3382.166667 | 1 |
| 0 | Shingeki no Kyojin Season 3 | 10257.600000 | 2 |
| 1 | Kimetsu no Yaiba | 4872.259259 | 2 |
| 2 | One Punch Man Season 2 | 3825.666667 | 2 |
| 3 | Isekai Quartet | 2550.916667 | 2 |
| 4 | Hitori Bocchi no ○○ Seikatsu | 1643.750000 | 2 |
| 0 | Dr. Stone | 4207.291667 | 3 |
| 1 | Vinland Saga | 4027.791667 | 3 |
| 2 | Enen no Shouboutai | 2533.791667 | 3 |
| 3 | Tsuujou Kougeki ga Zentai Kougeki de Ni-kai Ko... | 1760.000000 | 3 |
| 4 | Dungeon ni Deai o Motomeru no wa Machigatte Ir... | 1641.583333 | 3 |
| 0 | Boku no Hero Academia Season 4 | 4608.181818 | 4 |
| 1 | Sword Art Online: Alicization - War of Underworld | 2264.833333 | 4 |
| 2 | Fate/Grand Order: Zettai Majuu Sensen Babylonia | 2143.090909 | 4 |
| 3 | Shinchou Yuusha: Kono Yuusha ga Ore Tueee Kuse... | 2067.833333 | 4 |
| 4 | Ore o Suki na no wa Omae Dake ka yo | 1840.363636 | 4 |
rank_2020 = rank_seasons(2020)
rank_2020
| anime | score | season | |
|---|---|---|---|
| 0 | Boku no Hero Academia Season 4 | 4224.571429 | 1 |
| 1 | Fate/Grand Order: Zettai Majuu Sensen Babylonia | 2351.200000 | 1 |
| 2 | Eizouken ni wa Te wo Dasu na! | 2117.833333 | 1 |
| 3 | Itai no wa Iya nano de Bougyoryoku ni Kyokufur... | 2000.166667 | 1 |
| 4 | Haikyuu!! To the Top | 1984.384615 | 1 |
| 0 | Kaguya-sama wa Kokurasetai?: Tensai-tachi no R... | 10105.000000 | 2 |
| 1 | Kaguya-sama wa Kokurasetai?: Tensai-tachi no R... | 9362.000000 | 2 |
| 2 | Kami no Tou | 8229.000000 | 2 |
| 3 | Kami no Tou: Tower of God | 8040.500000 | 2 |
| 4 | Otome Game no Hametsu Flag shika Nai Akuyaku R... | 3128.000000 | 2 |
| 0 | Re:Zero kara Hajimeru Isekai Seikatsu Season 2 | 12289.615385 | 3 |
| 1 | Yahari Ore no Seishun Love Comedy wa Machigatt... | 6253.833333 | 3 |
| 2 | The God of High School | 4913.384615 | 3 |
| 3 | Maou Gakuin no Futekigousha: Shijou Saikyou no... | 3780.916667 | 3 |
| 4 | Sword Art Online: Alicization - War of Underwo... | 3347.000000 | 3 |
| 0 | Shingeki no Kyojin: The Final Season | 16821.500000 | 4 |
| 1 | Jujutsu Kaisen | 6458.266667 | 4 |
| 2 | Haikyuu!! To the Top 2nd Season | 4450.000000 | 4 |
| 3 | Haikyuu!!: To the Top Part 2 | 2831.363636 | 4 |
| 4 | Higurashi no Naku Koro ni [Reboot only thread] | 2758.666667 | 4 |
rank_2021 = rank_seasons(2021)
rank_2021
| anime | score | season | |
|---|---|---|---|
| 0 | Shingeki no Kyojin: The Final Season | 18219.307692 | 1 |
| 1 | Re:Zero kara Hajimeru Isekai Seikatsu Season 2... | 12320.250000 | 1 |
| 2 | Jujutsu Kaisen | 10981.727273 | 1 |
| 3 | Mushoku Tensei: Isekai Ittara Honki Dasu | 8043.727273 | 1 |
| 4 | Horimiya | 6959.461538 | 1 |
| 0 | 86 EIGHTY-SIX | 7757.090909 | 2 |
| 1 | Vivy: Fluorite Eye's Song | 5536.461538 | 2 |
| 2 | Fumetsu no Anata e | 5449.750000 | 2 |
| 3 | Ijiranaide, Nagatoro-san | 4158.750000 | 2 |
| 4 | Hige wo Soru. Soshite Joshikousei wo Hirou. | 3315.076923 | 2 |
Since we have both score of a submission and score of a comments, I ranked the animes with
- mean of each submission’s score
import plotly.express as px
import plotly.io as pio
pio.renderers.default='iframe'
top5_by_score = mean_scores.groupby('season').apply(lambda x: x.sort_values(by='score', ascending=False, na_position='first').head(5).reset_index()).droplevel(0)
fig_1 = px.line(
top5_by_score,
x=top5_by_score.index,
y='score',
color='season',
symbol='season',
hover_data=['anime'],
labels={
"index": "Rank",
"score": "Mean of Submission Score",
"season": "Season"
},
)
fig_1.show()
- mean of total comments' score under the same submission
sta_19.fillna(0, inplace=True)
mean_com_count = sta_19.groupby('anime').agg({'com_count': 'mean', 'season': 'min'})
top5_by_com_count = mean_com_count.groupby('season').apply(lambda x: x.sort_values(by='com_count', ascending=False, na_position='first').reset_index().head(5)).droplevel(0)
fig_2 = px.line(
top5_by_com_count,
x=top5_by_com_count.index,
y='com_count',
color='season',
symbol='season',
hover_data=['anime'],
labels={
"index": "Rank",
"com_count": "Mean of comment's count",
"season": "Season"
},
)
fig_2.show()
- median of total comments' score under the same submission
med_com_score = sta_19.groupby('anime').agg({'com_median': 'mean', 'season': 'min'})
top5_by_com_score_med = med_com_score.groupby('season').apply(lambda x: x.sort_values(by='com_median', ascending=False, na_position='first').reset_index().head(5)).droplevel(0)
fig_3 = px.line(
top5_by_com_score_med,
x=top5_by_com_score_med.index,
y='com_median',
color='season',
symbol='season',
hover_data=['anime'],
labels={
"index": "Rank",
"com_median": "Median of comment's Score",
"season": "Season"
},
)
fig_3.show()
- total number of comments under the same submission
sta_19.fillna(0, inplace=True)
mean_com_score = sta_19.groupby('anime').agg({'com_mean': 'mean', 'season': 'min'})
top5_by_com_mean = mean_com_score.groupby('season').apply(lambda x: x.sort_values(by='com_mean', ascending=False, na_position='first').reset_index().head(5)).droplevel(0)
fig_4 = px.line(
top5_by_com_mean,
x=top5_by_com_mean.index,
y='com_mean',
color='season',
symbol='season',
hover_data=['anime'],
labels={
"index": "Rank",
"com_mean": "Mean of comment's Score",
"season": "Season"
},
)
fig_4.to_html("")
fig_4.show()
So we now can see that Each of these metric would produce a relatively different result. In order to test if we should keep both of them in our ranking model as metric, I tested if they are relevant, particularly mean of submission’s score and mean of comment’s score.
sta_19['comment_total'] = sta_19['com_mean'] * sta_19['com_count']
sta_19.plot.scatter(x='com_mean', y='score', logy=True, logx=True)
sta_19.plot.scatter(x='comment_total', y='score', logy=True, logx=True)
<AxesSubplot:xlabel='comment_total', ylabel='score'>
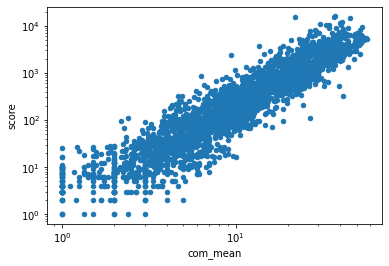
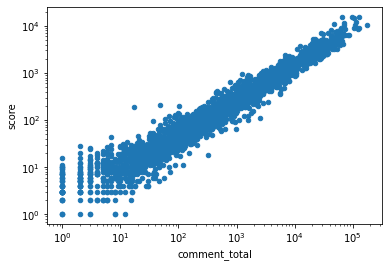
Apparently, both the mean of and the sum of the comments' score are highly relevant to submission’s score, thus we only need to rely on the score of the submission to rank the animes. Then we can rank the anime in each season from 2019 to 2021 using the mean score of the discussion submission post.
Now we can rank the top 5 animes in each season of each year as below
- 2019
rank_2019 = rank_seasons(2019)
rank_2019
| anime | score | season | |
|---|---|---|---|
| 0 | Kaguya-sama wa Kokurasetai: Tensai-tachi no Re... | 7204.916667 | 1 |
| 1 | Mob Psycho 100 Season 2 | 6884.000000 | 1 |
| 2 | Yakusoku no Neverland | 4324.083333 | 1 |
| 3 | Tate no Yuusha no Nariagari | 3800.400000 | 1 |
| 4 | Tensei shitara Slime Datta Ken | 3382.166667 | 1 |
| 0 | Shingeki no Kyojin Season 3 | 10257.600000 | 2 |
| 1 | Kimetsu no Yaiba | 4872.259259 | 2 |
| 2 | One Punch Man Season 2 | 3825.666667 | 2 |
| 3 | Isekai Quartet | 2550.916667 | 2 |
| 4 | Hitori Bocchi no ○○ Seikatsu | 1643.750000 | 2 |
| 0 | Dr. Stone | 4207.291667 | 3 |
| 1 | Vinland Saga | 4027.791667 | 3 |
| 2 | Enen no Shouboutai | 2533.791667 | 3 |
| 3 | Tsuujou Kougeki ga Zentai Kougeki de Ni-kai Ko... | 1760.000000 | 3 |
| 4 | Dungeon ni Deai o Motomeru no wa Machigatte Ir... | 1641.583333 | 3 |
| 0 | Boku no Hero Academia Season 4 | 4608.181818 | 4 |
| 1 | Sword Art Online: Alicization - War of Underworld | 2264.833333 | 4 |
| 2 | Fate/Grand Order: Zettai Majuu Sensen Babylonia | 2143.090909 | 4 |
| 3 | Shinchou Yuusha: Kono Yuusha ga Ore Tueee Kuse... | 2067.833333 | 4 |
| 4 | Ore o Suki na no wa Omae Dake ka yo | 1840.363636 | 4 |
- 2020
rank_2020 = rank_seasons(2020)
rank_2020
| anime | score | season | |
|---|---|---|---|
| 0 | Boku no Hero Academia Season 4 | 4224.571429 | 1 |
| 1 | Fate/Grand Order: Zettai Majuu Sensen Babylonia | 2351.200000 | 1 |
| 2 | Eizouken ni wa Te wo Dasu na! | 2117.833333 | 1 |
| 3 | Itai no wa Iya nano de Bougyoryoku ni Kyokufur... | 2000.166667 | 1 |
| 4 | Haikyuu!! To the Top | 1984.384615 | 1 |
| 0 | Kaguya-sama wa Kokurasetai?: Tensai-tachi no R... | 10105.000000 | 2 |
| 1 | Kaguya-sama wa Kokurasetai?: Tensai-tachi no R... | 9362.000000 | 2 |
| 2 | Kami no Tou | 8229.000000 | 2 |
| 3 | Kami no Tou: Tower of God | 8040.500000 | 2 |
| 4 | Otome Game no Hametsu Flag shika Nai Akuyaku R... | 3128.000000 | 2 |
| 0 | Re:Zero kara Hajimeru Isekai Seikatsu Season 2 | 12289.615385 | 3 |
| 1 | Yahari Ore no Seishun Love Comedy wa Machigatt... | 6253.833333 | 3 |
| 2 | The God of High School | 4913.384615 | 3 |
| 3 | Maou Gakuin no Futekigousha: Shijou Saikyou no... | 3780.916667 | 3 |
| 4 | Sword Art Online: Alicization - War of Underwo... | 3347.000000 | 3 |
| 0 | Shingeki no Kyojin: The Final Season | 16821.500000 | 4 |
| 1 | Jujutsu Kaisen | 6458.266667 | 4 |
| 2 | Haikyuu!! To the Top 2nd Season | 4450.000000 | 4 |
| 3 | Haikyuu!!: To the Top Part 2 | 2831.363636 | 4 |
| 4 | Higurashi no Naku Koro ni [Reboot only thread] | 2758.666667 | 4 |
- 2021 (First two season)
rank_2021 = rank_seasons(2021)
rank_2021
| anime | score | season | |
|---|---|---|---|
| 0 | Shingeki no Kyojin: The Final Season | 18219.307692 | 1 |
| 1 | Re:Zero kara Hajimeru Isekai Seikatsu Season 2... | 12320.250000 | 1 |
| 2 | Jujutsu Kaisen | 10981.727273 | 1 |
| 3 | Mushoku Tensei: Isekai Ittara Honki Dasu | 8043.727273 | 1 |
| 4 | Horimiya | 6959.461538 | 1 |
| 0 | 86 EIGHTY-SIX | 7757.090909 | 2 |
| 1 | Vivy: Fluorite Eye's Song | 5536.461538 | 2 |
| 2 | Fumetsu no Anata e | 5449.750000 | 2 |
| 3 | Ijiranaide, Nagatoro-san | 4158.750000 | 2 |
| 4 | Hige wo Soru. Soshite Joshikousei wo Hirou. | 3315.076923 | 2 |
Furthermore, we then can generate the ranks in all three years we have in a facet plot which is categorized by year:
rank_2019['year'] = 2019
rank_2020['year'] = 2020
rank_2021['year'] = 2021
total = rank_2019.append(rank_2020).append(rank_2021)
fig = px.line(
total,
x=total.index,
y='score',
color='season',
symbol='season',
facet_col='year',
hover_data=['anime'],
labels={
"index": "Rank",
"score": "Mean of Submission Score",
"season": "Season"
},
)
sp = total[total['anime'].str.contains('Shingeki no Kyojin')]
sp_data = px.scatter(
sp,
x=sp.index,
y='score',
text="anime",
facet_col='year'
).update_traces(mode="text")["data"]
for trace in sp_data:
fig.add_trace(trace)
save_ploty(f"{Export_Path}/trend.html", [fig])
fig.show()
Based on the facet plot above, over the years, the community is actually more and more active, as we can see that the mean of the score is increasing.
And we can see that some series is extremely welcomed in fact, the season 3 and season 4 (which has 23 episodes) of Shingeki no Kyojin were released in season 2 2019, season 4 2020 and season 1 2021, The average score they received are significantly higher than the usual animes.
Therefore, Apart from knowing which Anime is the hotest in it’s own season we can also see that Shingeki no Kyojin is the most popular anime in the community.
Explore What Would Make an Anime Hot
Since in the full dataset, we were only given the meta data of each submission and comment and the text data set is only a small subset of the full dataset. We are unable to do much further analysis to detect what would make an anime popular.
Luckily, during doing this project, I also encountered an interesting dataset anime-offline-database, which contains the tag of each anime so we can pick up the tag data from it.
The columns I care about are:
title: The name of animetags: list of tags of the anime
we can try look into what kind of theme or subject would make a anime popular, in other words, try to connect the presence of tag in the anime with the score it can and build a model to predict the score with tag data.
Merge the Records
The only difficulty is that name of the same anime would be slightly different in two dataset, making us hard to do the exact match. The common differences are:
- Lower cases vs. Upper cases
- Series numbering
- Translation Habits
Some examples are shown as below:
merged_table[merged_table['anime'] != merged_table['anime_title']][['anime', 'anime_title']].head()
| anime | anime_title | |
|---|---|---|
| 0 | 3D Kanojo: Real Girl Season 2 | 3D Kanojo: Real Girl 2nd Season |
| 2 | Africa no Salaryman | Africa no Salaryman (TV) |
| 4 | Aikatsu Friends! | Aikatsu on Parade! |
| 8 | Ani ni Tsukeru Kusuri wa Nai! Season 3 | Ani ni Tsukeru Kusuri wa Nai! 3 |
| 14 | BEM | EMOMOMO |
So I solved the problem with Python’s built-in difflib to get the closet match of anime name in two dataset, then try to merge the animes which have name presented in the search result.
def find_closet(x):
# perform fuzzy search on the anime title from reddit dataset
# with title in the anime-offline-database
res = difflib.get_close_matches(x, anime_meta_year['title'], cutoff=0.4)
if len(res) == 0:
return np.nan
return res[0]
As a result, only 50 animes were dropped due to no matchin, which is pretty good given the orginal total number of animes in the reddit is 537.
Regression With Linear Model
After merging the tables, by applying explode() and pivot(), we can obtain a tag matrix, where columns are the presented tags and index are the anime names.
tag_matrix = tags.pivot('anime', columns='tags', values='present').fillna(0)
tag_matrix = tag_matrix.sort_index(axis=1, key=lambda x: tag_matrix[x].sum(), ascending=False)
tag_matrix.head()
| tags | comedy | action | drama | fantasy | slice of life | present | based on a manga | male protagonist | female protagonist | shounen | ... | shounen ai | soccer | shounen-ai | flat chested | shrine maiden | flash animation | skateboarding | slow when it comes to love | fake romance | exhibitionism |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| anime | |||||||||||||||||||||
| 100-man no Inochi no Ue ni Ore wa Tatte Iru | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.43: Seiin Koukou Danshi Volley-bu | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 22/7 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3D Kanojo: Real Girl Season 2 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| A3! Season Autumn & Winter | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 717 columns
In this case, we would explore with the Linear and Logistic Regressions in the linear model. We can split data into three parts - 70% as training data, 15% as test data and 15 % as validation data.
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def rating_test(start, end, useLinear=True, step=1):
test_mses = []
vali_mses = []
if useLinear:
Model = LinearRegression
else:
Model = LogisticRegression
for i in range(start, end, step):
reg = Model().fit(train_set.iloc[:, 0:i], train_y)
test_mses.append(mean_squared_error(test_y, reg.predict(test_set.iloc[:, 0:i])))
vali_mses.append(mean_squared_error(vali_y, reg.predict(vali_set.iloc[:, 0:i])))
test_mses = pd.Series(test_mses, index=[i for i in range(start, end, step)], name='Training MSE').rename_axis('n_features')
vali_mses = pd.Series(vali_mses, index=[i for i in range(start, end, step)], name='Validation MSE').rename_axis('n_features')
return test_mses, vali_mses
test_mses, vali_mses = rating_test(1, 30)
test_mses.plot.line(grid=True, marker='o', legend=True)
vali_mses.plot.line(grid=True, marker='^', legend=True)
<AxesSubplot:xlabel='n_features'>
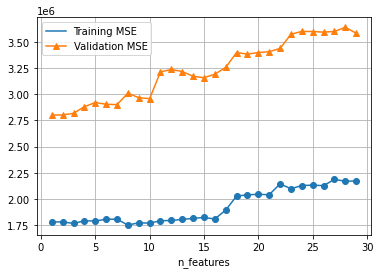
From the plot of MSE between predicted y and actual y is over $10^6$, so apparently, Linear Regression won’t work well with this data set.
Now, let’s test with Logistic Regression
test_mses, vali_mses = rating_test(1, 30, False)
test_mses.plot.line(grid=True, marker='o', legend=True)
vali_mses.plot.line(grid=True, marker='^', legend=True)
<AxesSubplot:xlabel='n_features'>
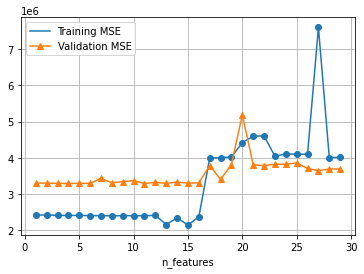
Similarly, Logistic Model doesn’t work well on this dataset.
Therefore, we cannot use the simple classifiers to predict scores of an anime.
Conclusion
With given reddit dataset, it’s possible for us to determine what are the hottest animes over different period of time and find out how to rank the top n animes for simple recommendation system. But there are still some limitations using this dataset, such as detect what would be the worst anime, since the score mostly reflects how people are happy to discuss this submission but we are unable to tell what’s the attitude of people towards to a TV series. For example, if the quality of an episode is extremely, users might go to the submission and leave comments like analyzing why it’s bad and compilations about the plots which may still receive a very good score as a result. It might be a good idea to combine with sentiment score of the texts in the thread to detect if people are complaining, praising or just don’t care about the episode.
I also attempted to use the linear model to find potential connection between the tags of animes and mean score of anime episode’s discussion submission. However, it turns out these two models didn’t work well given data, thus it may require some more powerful models to test if we can find some connections.