This post is about part A of Lab3 of MIT 6.824, Distributed Systems. For previous two parts, please refer to the posts about the Lab 1 and 2 under the tag Distributed System. In this post, we are to build a fault tolerant key-value services on top of Raft.
Overview
The functions we need to achieve are in fact very simple. It will need three functions:
Put(key, value): Create a new key-value pair. Replace with thevlaueif the keys exists in the map;Append(key, value): If thekeyexists in the map, appendvalueto the end of old value. If not, do as whatPut()does;Get(key): Return the value ifkeyexists in the map. Otherwise, return an empty string.
If it’s a singe server app, it won’t take much time to implement. However, for fault tolerance, we will have to maintain multiple kv servers so that the service is available. Thus the real problem now is how to coordinate and synchronize the data between the servers through Raft.
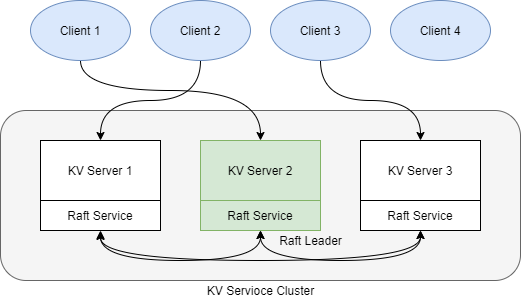
As diagram illustrated above, we will have a server cluster, where raft service can see each other to do the election and log replications but the kv server can only communicate with its only Raft service in the cluster. Clients will randomly send requests to any kv servers. However, only the kv server whose raft is the leader will proceed the request and send back the data. All other kv servers will reject the request and ask the client to try other kv server.
Client Side
Let us begin with something easy first. The job of client is very simple, sending requests to one kv server, waiting for response. If timeout or receive any error, retry with other kv server.
As we will have multiple clients running parallelly, to make sure it’s able to know which client sent the request. We will assign each client an ID generated by nrand(). And there is also a chance that the same request might be sent multiple times. To identify the duplicate requests, each request should have an ID generated by nrand(), so that kv server is able to recognize the duplicate requests.
Besides, to speed up the later requests, the client can cache the last seen leader ID (which is basically the index of server in ck.servers), so it doesn’t have to try from the first server.
Thus we can define the client as below:
type Clerk struct {
servers []*labrpc.ClientEnd
serverNum int
clientId int64 // client's own uid
lastLeaderId int // The leader id last heard
}
When clients need to send the Get or PutAppend request, we can have Get defined like below as an example:
// common.go
type GetArgs struct {
MsgId int64
ClientId int64
Key string
}
type GetReply struct {
Key string
Value string
Err string
}
// client.go
func (ck *Clerk) Get(key string) string {
var reply GetReply
args := GetArgs{
MsgId: nrand(),
ClientId: ck.clientId,
Key: key,
}
// Send Get Rpc and wait for the response
// If timeout or error wrong leader, try anoterh server
}
Server Side
In the entire server cluster, only the server with the leader of Raft services can procced the requests from clients and send back the actual data to client. All other servers acts as back-up, only proceeding the request sent from the channel kv.applyCh and rejecting immediately any requests if finding itself not a leader in Raft services after calling rf.Start()
Those we can illustrate the logic of the cluster as below:
graph TB
client
subgraph cluster
kv1[KV Leader]
kv2[KV Follower 1]
kv3[KV Follower 2]
rf_l(["Raft Leader"])
rf_1(["Raft Follower 1"])
rf_2(["Raft Follower 2"])
end
client --> | a1. New request| kv1
kv1 --> |a2. Ask to log the requst| rf_l
rf_l --> |a3. Append the new log| rf_1 & rf_2
rf_l --> |a4. complete the request from apply | kv1
rf_1 --> |a5. Send backed up load to its kv server | kv2
rf_2 --> |"as (a5)"| kv3
kv1 --> |"a6. Success (with data return)"| client
client -. b1. New request .-> kv2
kv2 -. b2. Falied due to not leader .-> client
In section a, the request is sent to leader and got proceeded in the all the nodes in the cluster but in section b, the request is rejected as
KV Follower 1is not the leader in the cluster.
Besides, another requirement is that duplicate requests must be omitted. Thus for each client, we need to cache the last request id it made.
Thus we can have the struct KVServer defined as:
type KVServer struct {
mu sync.Mutex
me int
dead int32 // set by Kill()
// Raft Server
rf *raft.Raft
applyCh chan raft.ApplyMsg
persister *raft.Persister
// snapshot if log grows this big
maxraftstate int
// sotre the key/value pairs in a map
data map[string]string
// keep a chan for each request submitted to raft. Delete if timeout or it's done
waitChs map[int64]chan ApplyReply
// cache the last request invoked by the client
lastApplies map[int64]int64
}
Leader Proceeding the Requests
All the operation won’t be applied to kv.data directly after receiving the request. Leader KVServer will first submit the request to Raft by rf.Start() and make a wait channel in kv.waitChs for this new request, for channel we need a timer to ensure that the goroutine Get() and PutAppend() will stop if taking too long to execute the request and can know the result of the execution without requiring additional lock for reading/updating the data. All the KVServer will execute the operation until they got the committed log sent back by Raft through kv.applyCh and send the execution result through kv.waitChs the goroutine Get() and PutAppend().
You also need to define a new struct or add some new fields to ApplyMsg , so that KVServer can know request client id, request message id and other data help you identify duplications.
Then we can have:
func (kv *KVServer) start(args applyArg) (rep ApplyReply) {
index, term, isLeader := kv.rf.Start(args)
// Reject if not leader
if !isLeader {
return ApplyReply{Err: ErrWrongLeader}
}
kv.lock()
// Create a channel to watch if raft has reached
// agreement for this request
ch := make(chan ApplyReply)
kv.waitChs[args.MsgId] = ch
kv.unlock()
// Wait until either timeout or getting response
// from WaitCh
}
// goroutine to monitor the kv.applyCh
func (kv *KVServer) waitApplyChan() {
for !kv.killed() {
// Wait the new logged request from raft
msg := <-kv.applyCh
submittedReq := msg.Command
// acquire the log as we need to update and read kv.data
kv.lock()
// Check if it's a duplicate msg have seen before
// You have to check it here since, the followers
// can only see new req through kv.applyCh
// With the op value and key(/value) in the req, update your data
// use the waitCh to tell KVServer to send back the response
// status cide and retrived data to client
if ch, ok := kv.waitChs[submittedReq.MsgId]; ok {
ch <- ApplyReply{Err: err, Value: value}
}
kv.unlock()
}
}
Changes in Raft
A very important thing to remember in this Lab3A is that KVServer will lose all the data once it dies. The way to recover to the previous state are two:
- Raft replays all the committed logs it has from 0 to
rf.commitIndex; - Use RPC
InstallSnapshot, which we are to implement in the next lab.
Thus the easiest solution for recovering the data of kv is that rf.lastApplied will be reset to 0 once rebooting, which indicates that kv has no data at all. So once Raft needs to send new ApplyMsg to kv, we should send rf.log[rf.lastApplied+1:newCommitIndex+1] and mark all the logs whose index
\(\leq\)
oldCommitIndex invalid data as tester has seen these logs already.