This post is about part A and B of Lab2 of MIT 6.824, Distributed Systems. It is about the implementation of Raft. Here in these two part, we only discuss the section up to the end of section 5 in the paper.
Brief Idea
In GFS or MapReduce, we have one single Master to manage the entire system. However, there is still a chance that the Master encounters some error or other issues. We than need a cluster to avoid this single point failure. And again, as in the distributed system, it’s inevitable to have some nodes failed. We need a way to keep the requests and results contestant across the cluster as recovery and always have one leader to take the requests from the users.
Raft is a consensus algorithm for managing a replicated log. Here log refers to requests to be backed up in the cluster. Each node maintains a list of log of the same order. As long as morn than half of the nodes are alive in the network, the cluster can still be functional.
The system we are to build follows the rules illustrated as this chart in the paper:

Part A: Election And State Transiting
There are three different states in Raft: leader, follower and candidate. In a working Raft network, it is only allowed to have one leader to take the request and try to back up the request to the other nodes. And all other nodes become follower to receive log back up from leader and maintain a timer to start a leader election if not listening back from the leader after a certain time by converting itself to be an candidate. And Raft uses an monophonically increasing integer as term number to tell different leaders.
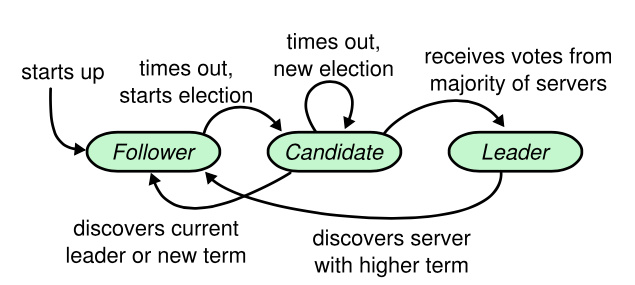
Following the state chart above and RequestVoteRPC, we can see what we need to implement:
1) Initially, Set all the Raft struct to be follower. Each of them start a timer electionTimeOut of random duration. After timer time out, follower turns itself to be candidate, increase term by 1 and start a leader election;
2) candidate uses RequestVoteRPC to ask all the peers to vote; if winning the votes from the majority, turning itself to be new leader and start the go routine broadcastHeartbeat to tell all the peers they should reset the timer electionTimeOut and wait for the commands;
3) If unable to win the majority in the electionTimeOut, increase term by 1 and restart a leader election.
Thus, the Raft struct should be defined as:
const (
Follower = iota
Leader
Candidate
)
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
applyCh chan ApplyMsg
state RafeState
currTerm int
votedFor int
lastUpdate time.Time
log []LogEntry
commitIndex int
lastApplied int
// Leader use, reset for each term
nextIndex []int // index of the next log entry to send to that server
matchIndex []int // index of highest log entry known to be replicated on server
// Candidate use
voteCount int // Increase by 1 if revice a vote from a peer.
}
A rule in the figure 2 that all the nodes must follow:
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
So that term number can keep up-to-date in the entire network and an out-dated leader can know it should jump to a higher term.
Election Restrictions
Besides, as the rules stated in the figure 2 of paper and section 5.4.1, we have several rules to implement as election restriction.
For candidate, it loses an election if one of the following happens:
1) It’s killed. rf.killed() == true;
2) Some RequestVoteRPCReply has a higher term number than it’s currTerm;
3) Receive AppendEntryRPC with a higher term number than it’s currTerm.
For follower, it rejects the RequestVoteRPC if one of the following happens:
1) the request from the candidate with a lower term;
2) the request from the candidate which comes later and belongs to the same term;
3) the last entry having a higher term;
4) the logs longer than candidate when having the same term number.
VoteFor
The voteFor should be carefully managed, as failing to follow the rule in the figure 2 would lead to unexpected election result, especially when the nodes need to use records to persisted record to reboot in the part C.
If the node is a candidate, set its voteFor = rf.me
If the node receives a RequestVoteRPC and replies voteGranted == true, then it should set its voteFor = candidateId
If the node becomes a followers only because receiving a RPC request from a node in a higher term and update itself to a follower , then it should set its voteFor = -1
Part B: Log Replication
In this part, Raft struct will receive logs from the test by rf.Start() to reach agreement among the peers and the log replication is one of the most important part of Raft.
The logic is quite straightforward:
1) leader receive a new command from the user through rf.Start() and appends this new log to the end of the rf.log[];
2) leader can call peers' AppendEntryRPC immediately after receiving one new log but also wait until leader calls broadcastHeartbeat to send all the new logs together, which is a good way to avoid calling AppendEntryRPC too frequently and have concurrent update issues with rf.nextIndex[] and rf.matchIndex;
3) follower receives a AppendEntryRPCArgs, comparing rf.log[args.PreLogIndex].Term with args.PreLogTerm. If equaling, follower can reach a agreement up to args.PreLogIndex then append the new entries in the request:
append(rf.log[:args.PreLogIndex+1], args.Entries...)
Otherwise, follower replies with false, asking leader to decrease the args.PreLogIndex recursively until finding some index where leader and follower can reach an agreement. follower should abort the logs between args.PreLogIndex and rf.lastApplied;
4) After appending new log entries successfully, leader updates index value of rf.matchIndex[peerIdx] and then update its commitIndex by choosing a N where a majority of rf.matchIndex[i] >= N and N > rf.commitIndex;
5) In the next broadcastHeartbeat, follower receives the leader’s new commitIndex in args.LeaderCommit. If args.LeaderCommit > rf.commitIndex, then follower should update its commitIndex to be:
min(args.LeaderCommit, rf.lastApplied)
6) Both leader and follower need to send logs between old and new commit Index to the channel ApplyMsg for testing.
We also need to be careful about the logic of handler AppendEntries:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// Update state as term number in the args
if args.Term < rf.currTerm || (args.Term == rf.currTerm && rf.state == Leader) {
// If receving a log with outdated term number, rejecting directly
// If appearing 2 leaders, rejecting
reply.IsSuccess = false
reply.Term = rf.currTerm
return
} else if args.Term > rf.currTerm {
// See a higher term turn to follower of term
rf.setStateFollower(args.Term, -1)
} else {
// If same term just refresh the update time
rf.lastUpdate = time.Now()
}
// Only with a valid term number, it should be considered as hearing from the leader
// Update rf.log[]
if args.PreLogIndex > rf.lastApplied {
// The expected PreLogIndex > actual last index on follower. Ask for decrement
reply.IsSuccess = false
} else if rf.log[args.PreLogIndex].Term == args.PreLogTerm {
// Able to reach agreement at the PreLogIndex, concat rf.log
reply.IsSuccess = true
//...
} else if rf.log[args.PreLogIndex].Term != args.PreLogTerm {
// Unable to reach agreement at the PreLogIndex due to differetn term number. Ask for decrement
reply.IsSuccess = false
}
// If success on agrement and args.LeaderCommit > rf.commitIndex,
// update follower's commit index and send apply msg to tester
return
}
Tips
-
Use go routine to send RPC parallelly. Also use go routine to send
ApplyMsgas after commitment, they are safe to leave them. -
Split the
raft.gointo multiple go files by the RPC types, as for each RPC you may need one handler forfollowerand multiple functions forleader; -
For node state transiting, a good idea is to use set methods to group all the variables you need to update for state change so you won’t miss some of them.
Use changing to Follower as an example:
func (rf *Raft) setStateFollower(term, voteFor int) { rf.currTerm = term rf.votedFor = voteFor // Update last time hear from the leader rf.state = Follower rf.lastUpdate = time.Now() // Start a new election timer go rf.electionTimeOut(term) } -
Use
sort.Slice()to helpleaderfind newcommitIndex; -
Election and heartbeat timers are suggested to implement using
for {}instead oftime.NewTimer. I also pass in atermto the timer so that when using set methods to update node’s state, you don’t have to warry about if you need to restart a new timer or not.Use heartbeat as an example:
const ( HeartbeatInterval = 120 * time.Millisecond ) func (rf *Raft) broadcastHeartbeat(term int) { for !rf.killed() { rf.mu.Lock() // Stop sent heartbeats if not a leader or has jumped to another term if rf.state != Leader || rf.currTerm > term { rf.mu.Unlock() break } // Some other operations in between... // Send heartbeat to all other peers for i, _ := range rf.peers { if i == rf.me { continue } // You can construct AppendEntriesArgs here or in the function go rf.sendAppendEntries(i) } rf.mu.Unlock() time.Sleep(HeartbeatInterval) } } -
Always check
Raftstruct’s state and return value ofrf.killed()after acquiring the lock. Return the function of break the loop if state changed or being killed.